Yapay Zeka İçin İçerik Tasarımı: 2026'da Yapı ve Schema Markup Neden Backlinklerden Daha Önemli
Yapay zekalar insanlar gibi okumaz, veriyi parse eder. ChatGPT, Perplexity ve Google AI'ya içeriğini temiz HTML hiyerarşisi, tablolar, listeler ve JSON-LD ile gümüş tepside nasıl sunarsın.

Cagri Ersöz
Cagri Ersöz, Hannover'deki dijital ajans Storyable'ın kurucusu ve genel müdürüdür. Satış psikolojisine dayalı web tasarımı ve full-stack geliştirme (Vue.js, Nuxt, React) deneyimiyle KOBİ'ler için 50'den fazla dijital projeyi hayata geçirmiştir. Uzmanlık alanları: dönüşüm optimizasyonu, yapay zeka entegrasyonu ve veri odaklı pazarlama.
Şimdi İletişime GeçBu makalenin içeriği↓
Web siten bir kelime duvarı. İnsan gözü için anlaşılır, yapay zeka için bir bilmece. Yapay zeka için içerik tasarımı basit bir gerçekle başlar: ChatGPT, Perplexity ve Google AI Overviews okumaz – parse eder. Bunu anlamayan, 2026'da kendisini bulamayan bir hedef kitle için yazıyor.
Storyable olarak Hannover'da bunu her gün görüyoruz: Müşteriler beş haneli rakamları backlinklere yatırırken, sayfalarında tek bir geçerli Schema Markup yok. Sonuç tahmin edilebilir – Google'da orta sıralarda yer alıyorlar ve hiçbir yapay zeka tarafından kaynak olarak alıntılanmıyorlar. Yapılandırılmış veri ve semantik HTML süs değil. Diğer her şeyi taşıyan temel.

„2026'da Schema Markup'ı olmayan bir sayfa, vitrini olmayan bir mağaza gibi: İçerik harika olabilir – ama kimse içine bakmaz. Backlinkler seni şehre getirir. Schema Markup seni alışveriş caddesine getirir."
Backlinkler Kral Sinyal Rolünü Neden Kaybetti
Yirmi yıl boyunca backlink, SEO'nun en sert para birimiydi. Daha çok bağlantı, daha yüksek sıralama. Denklem bu kadar basitti. 2026'da artık doğru değil – modern yapay zeka sistemlerinin işleyişiyle ilgili üç nedenden ötürü.
- LLM'ler birikmiş link profilleri üzerinden değil, gerçek zamanlı sıralar. ChatGPT Search güncel ilk sonuçları çeker ve onları netlik ve yapıya göre değerlendirir. 800 backlink'i olan 5 yıllık bir makale, link profili olmayan taze ve temiz yapılandırılmış bir makaleye karşı kaybeder.
- Google'ın 2024/2025 kendi açıklamaları: John Mueller defalarca backlinklerin „artık en önemli sıralama faktörlerinden biri olmadığını" doğruladı. Helpful Content, E-E-A-T ve yapısal netlik öne geçti.
- Yapay zeka katmanı link profillerini tamamen atlar. ChatGPT bir cevap ürettiğinde model „En çok backlink kim tarafından alındı?" sorusunu sormaz, „Bu soruya en net bilgiyi hangi kaynak veriyor?" sorusunu sorar. GEO – Generative Engine Optimization konusunun özü tam olarak bu.
Princeton GEO Araştırması (Aggarwal vd., 2024) kanıtı sundu: Net yapıya sahip içerikler (listeler, tablolar, kaynaklı istatistikler) LLM cevaplarında yüzde 40 daha sık alıntılandı – Domain Authority veya backlink profilinden bağımsız olarak. Karar veren makine olduğunda yapı, otoriteyi yener.
Yapay Zekalar İçeriği Gerçekte Nasıl „Okur" – Teknik Bir Bakış
Çözümlere geçmeden önce arka planda neler olduğunu anlaman gerek. Bir LLM bir web sayfasını üç adımda işler – ve her adımda kod tasarımınla görünür kalıp kalmayacağına sen karar verirsin.
Adım 1: Crawler HTML'i Çeker
GPTBot, ClaudeBot, PerplexityBot veya Googlebot sayfanı çeker. Gördükleri tarayıcıda gördüğün şey değil – render edilmiş HTML kaynağıdır. İçeriğin JavaScript ile sonradan yüklenirse (Client-Side Rendering), birçok yapay zeka crawler'ı hiçbir şey görmez. Storyable'da bu yüzden Nuxt.js ile Server-Side Rendering kullanıyoruz – böylece her kelime ilk HTML'de yer alır.
Adım 2: Parser Yapıyı Çıkarır
Parser hiyerarşi sinyalleri arar: H1, H2, H3, <article>, <section>, <table>, <ul>, <ol>. Bu öğelerden makine bir doküman ağacı kurar – içeriğinin iskeleti. Semantik HTML olmayan bir sayfa (tüm metinler <div> ve <span> içinde) ağaç değil, lapa verir. LLM'ler lapayı kopyalamaz.
Adım 3: Embedding Engine Metni Vektörlere Çevirir
Her paragraf, her liste, her tablo çok boyutlu sayı vektörlerine – embedding'lere – çevrilir. Bu vektörler kelimeleri değil, anlamı temsil eder. Yapılandırılmış içerikler daha net, daha yoğun vektörler üretir – ve cevap üretiminde önceliklendirilir.
HTML yapısı belirsiz olan bir sayfa bulanık embedding'ler üretir. Yapay zeka ana ifadenin ne olduğunu, neyin kanıt, neyin örnek olduğunu bilmez. Alıntı yapmak yerine bir sonraki kaynağa atlar. Sonuç: 0 görünürlük, 0 citation, 0 trafik. 30 plugin'li ve kırık hiyerarşili WordPress sayfaları arka arkaya tam olarak bunu yaşıyor.
Semantik HTML: Hafife Alınan Zorunlu Egzersiz
Tek bir Schema Markup eklemeden önce HTML'in doğru olmalı. Semantik HTML, her makinenin anladığı temel dildir – ücretsiz, plugin olmadan, JavaScript olmadan. İşte her Storyable projesinde uyguladığımız kurallar.
H1'den H6'ya: Hiyerarşi Pazarlık Konusu Değil
Bir sayfanın tam olarak bir H1'i vardır. Bu H1 Primary Keyword'ü içerir. Altında ana yönler için H2 bölümleri, altında derinleştirmeler için H3, altında detay noktaları için H4 gelir. Asla seviye atlama, asla H2'yi stil için kötüye kullanma.
| Element | Fonksiyon | Sayfa başına sıklık |
|---|---|---|
| H1 | Ana konu, Primary Keyword | Tam olarak 1 |
| H2 | Ana yönler, ikincil anahtar kelimeler | 4–8 |
| H3 | H2 altındaki derinleştirmeler | H2 başına 0–3 |
| H4 | Detay noktaları | Tutumlu |
| H5/H6 | Çok nadir kullanılır | Genelde 0 |
Temiz bir H hiyerarşisi, yapay zeka parser'larının uyguladığı ilk filtredir. Burada başarısız olan, sonraki her şeyde başarısız olur.
Listeler ve Tablolar LLM Mıknatıslarıdır
Listelerdeki (<ul>, <ol>) ve tablolardaki (<table>) yapılandırılmış veriler, aynı bilgileri içeren akıcı metne göre yapay zeka sistemleri tarafından 3-4 kat daha sık çıkarılır. Sebep: Zaten makine okunabilir şekilde yapılandırılmıştır.
- Sıralamalar: Her zaman
<ul>olarak, asla bir paragraf içinde satır sonu ile „•" olarak değil - Sıralı listeler: Her zaman
<ol>olarak, asla bir paragraf içinde „1." olarak değil - Karşılaştırmalar: Her zaman
<thead>ve<tbody>ile<table>olarak, asla manuel formatlanmış sütunlar olarak değil - FAQ cevapları: Her zaman
FAQPageschema'lı yapılandırılmış soru-cevap çiftleri olarak (aşağıya bak)
Article, Section, Aside: Hafife Alınan Etiketler
HTML5, neredeyse kimsenin doğru kullanmadığı semantik konteynerler getirdi:
<article>bir sayfanın ana içeriğini sarmalar (örn. bir blog yazısı)<section>bir Article içinde tematik olarak ilgili içerikleri gruplar<aside>tamamlayıcı içerikleri işaretler (sidebar'lar, bilgi kutuları)<nav>navigasyon öğelerini sarmalar- Resim altyazılı resimler için
<figure>+<figcaption>
Bu etiketleri doğru kullanan bir sayfa, yapay zekaya net bir anlam haritası verir. Bir <div> çölü vermez.
Her Storyable blog yazısını net H hiyerarşisi, semantik tablolar ve <figure> konteynerleri olan bir <article> bölümü etrafında inşa ediyoruz. Sonuç: Cluster yazılarımız son altı ayda Perplexity'deki citation rate'lerini üçe katladı – tek bir yeni backlink olmadan. Saf yapı işi, temiz markup ile birleşmiş.
JSON-LD ile Schema Markup: Makinelerin Gizli Dili
Semantik HTML görünür yapıdır. Schema Markup görünmez anlam katmanıdır. JSON-LD (JavaScript Object Notation for Linked Data) formatı üzerinden sayfanın <head>'ine içeriğinin makine okunabilir bir tanımını yerleştirirsin. Google 2015'ten beri JSON-LD'yi Microdata veya RDFa yerine açıkça öneriyor.
Bir JSON-LD Bloğunun Temel Anatomisi
Her schema bloğu aynı kalıbı izler: @context (her zaman Schema.org), @type (bu nedir?), ardından özellikler. Bir blog yazısı için örnek:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Yapay Zeka İçin İçerik Tasarımı",
"author": {
"@type": "Person",
"name": "Cagri Ersöz",
"url": "https://storyable.de/ueber-uns"
},
"datePublished": "2026-04-30",
"image": "https://storyable.de/images/blog/...",
"publisher": {
"@type": "Organization",
"name": "Storyable",
"url": "https://storyable.de"
}
}
Bu blok her makineye tek bir ifadede şunu söyler: „Bu bir makaledir, bu kişi tarafından, bu tarihte yazılmıştır, bu organizasyon tarafından yayımlanmıştır." Tahmin yok, yorumlama yok.
2026 İçin En Önemli Schema Tipleri
Gerçekten hangi schema'lara ihtiyacın var? İşte görünürlük kaldıracına göre sıralanmış zorunlu liste.
| Schema Tipi | Ne için | Kim ihtiyaç duyar |
|---|---|---|
| Organization | Şirket verileri, logo, sosyal profiller | Her web sitesi (site genelinde) |
| WebSite + SearchAction | Google'da Sitelinks-Searchbox | İç aramalı her web sitesi |
| BreadcrumbList | SERP'lerde yol navigasyonu | Her alt sayfa |
| Article / BlogPosting | Blog ve haber içerikleri | Her blog |
| FAQPage | FAQ bölümlerinden Featured Snippets | FAQ'lı her içerik sayfası |
| Person | Yazar profilleri, E-E-A-T sinyali | Her blog yazısı |
| LocalBusiness | Yerel görünürlük, Google Maps | Her yerel işletme |
| Product + Offer | Ürün verileri, fiyatlar, stok | Her online mağaza |
| Review / AggregateRating | SERP'lerde yıldız değerlendirmeleri | Mağazalar, hizmet sağlayıcılar |
| HowTo | Adım adım kılavuzlar | Eğitim içerikleri |
Storyable'da Organization + Article + FAQPage + BreadcrumbList + Person'ı her blog projesinde standart olarak uyguluyoruz – plugin kaosu olmadan temiz, geçerli çözüm olarak nuxt-schema-org üzerinden.
FAQPage Schema: En Hızlı Görünürlük Kaldıracı
Bu makaleden sadece bir şey alacaksan: FAQPage Schema'yı uygula. Hemen. Soru-cevap içerikli her sayfada. Etki ölçülebilir:
- FAQ içerikleri Google SERP'lerinde doğrudan Rich Result olarak gösterilir
- ChatGPT ve Perplexity cevapları üretimlerine bire bir çıkarır
- Standart snippet'lere kıyasla tıklama oranı yüzde 20–40 artar
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Schema Markup nedir?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Schema Markup standartlaştırılmış bir dildir..."
}
}
]
}
Önemli: Cevaplar tek başına anlaşılır olmalı. Google tarafından SERP'te doğrudan gösterilirler – sayfanın geri kalanının bağlamı olmadan.
Schema audit ister misin? Web siteni tüm ilgili schema tipleri için inceler, geçersiz uygulamaları tespit eder ve sana entegre etmeye hazır JSON-LD stack'i veririz. 7 gün içinde, Google Rich Results Test'inden geçen doğrulama belgesiyle.
En Sık Yapılan 5 Schema Hatası – ve Nasıl Önleyeceksin
Her gün fayda yerine zarar veren schema uygulamaları görüyoruz. İşte audit'lerde en sık bulduğumuz beş klasik.
Hata 1: Bağlantısız Genel Plugin Schema
Yoast veya RankMath sıklıkla Organization ile bağlantı olmadan Article-Schema üretir. Sonuç: Google makaleyi görür, ama yayıncıyı değil. Çözüm, tüm varlıkları tek bir JSON-LD bloğunda toplayan bağlantılı bir @id-grafıdır.
Hata 2: Geçersiz Cevaplı FAQPage Schema
FAQ cevapları Markdown linkleri, HTML etiketleri veya reklam metni içeremez. „Daha fazla bilgi için web sitemize bakın" cevabını ekleyen Google tarafından cezalandırılır – çoğunlukla Rich Result'ın tamamen kaldırılmasıyla.
Hata 3: image veya author Olmayan Article Schema
headline, image, author, datePublished, publisher zorunlu alanlardır. Biri eksikse schema geçersiz olarak işaretlenir ve göz ardı edilir. Test: Google Rich Results Test (search.google.com/test/rich-results).
Hata 4: Görünür İçerikle Eşleşmeyen Schema
99 € olarak fiyat işaretliyorsun, sayfada 149 € gösteriyorsun? Google bunu fark eder ve Rich Results'ı kalıcı olarak çeker. Schema, görünen şeyi tam olarak yansıtmalı.
Hata 5: Bir Sayfada Birden Fazla @type: Article
Bir sayfa bir makaledir. Üç Article-Schema ekleyen (örn. üç plugin aynı anda aktif olduğu için) crawler'ları ve LLM'leri kafalarını karıştırır. Sayfa başına bir temiz blok'a konsolide et.
Doğrulama zorunlu programı: Her yeni schema canlıya geçmeden önce iki doğrulayıcıdan geçmek ZORUNDA: 1) Google Rich Results Test (SERP görünürlüğü için), 2) Schema.org Validator (formal doğruluk için). Bunu her Storyable projesinde Deploy-Gate olarak kullanıyoruz – yeşil tik olmadan schema yok.
Varlıklar ve Knowledge Graph: Bir Sonraki Seviye
Schema Markup temeldir. Bir sonraki seviye, varlıklarının Google'ın Knowledge Graph'ı ve Wikidata ile bağlantısıdır. Varlık net tanımlı bir kavramdır – bir kişi, bir yer, bir marka, bir ürün. Schema'nda bilinen varlıklara açıkça link verirsen, içeriğin ile küresel bilgi grafı arasında köprü kurarsın.
Knowledge Graph Çapası Olarak sameAs Özelliği
Her Person ve Organization schema'sına bir sameAs listesi ekleyebilirsin. Varlığını Wikipedia, Wikidata, LinkedIn, Twitter/X, Crunchbase'deki muadilleriyle bağlar. Bu kimlik netliğini dramatik şekilde güçlendirir.
{
"@type": "Organization",
"name": "Storyable",
"sameAs": [
"https://www.linkedin.com/company/storyable",
"https://www.instagram.com/storyable.de",
"https://www.wikidata.org/wiki/QXXXXXX"
]
}
LLM'ler bu bağlantıları okur, eğitim korpuslarıyla karşılaştırır ve varlığı doğrulanmış ve güvenilir olarak sınıflandırır. Burada hiçbir şey bırakmayan, yapay zeka için tanınmamış kalır.
İçerikte Cross-Entity Linking
Akıcı metinde de varlıkları güçlendirebilirsin. Örnek: Sadece „Vue.js"den bahsetmek yerine, makale başına bir kez resmi Vue domain'ine veya Wikipedia maddesine link ver. Böylece LLM'lerin bağlam güçlendiricisi olarak değerlendirdiği semantik köprüler kurarsın – SEO vs. GEO Rehberimizde daha derin açıkladığımız bir prensip.
llms.txt – Yapay Zeka İçin Vitrin
2024 sonundan beri çoğu site sahibinin hâlâ uyuduğu yeni bir standart yerleşiyor: llms.txt ve llms-full.txt. Domain'inin kök dizininde basit bir Markdown dosyası – LLM'lere en önemli içeriklerinin küratörlü bir özetini verirsin.
llms.txt Şimdiden Neden Zorunlu
robots.txt'nin (erişimi düzenleyen) ve sitemap.xml'in (tüm URL'leri listeleyen) aksine llms.txt editöryal bir öneridir: İşte en iyi içeriklerim, bu sırayla, bu konularda. Standardı destekleyen LLM'ler (Anthropic araçları, daha yeni crawler'lar) bunu tercih edilen giriş noktası olarak kullanır.
# Storyable – Hannover Web Tasarım & SEO Ajansı
> Storyable, Vue/Nuxt ile custom-code web tasarım, SEO ve yapay zeka
> optimize içeriklerde uzmanlaşmış Hannover'dan bir dijital ajans.
## Ana Konular
- [Hannover Web Tasarım](https://storyable.de/tr/webdesign): Custom-code web tasarım...
- [Google SEO 2026](https://storyable.de/tr/google-seo): Arama motoru optimizasyonu...
- [GEO – Generative Engine Optimization](https://storyable.de/tr/blog/seo-vs-geo-2026-chatgpt-anahtar-kelimeler)
## En Önemli Makaleler
- [Yapay Zeka İçin Schema Markup](https://storyable.de/tr/blog/yapay-zeka-icin-icerik-tasarimi-...)
Format basit. Stratejik değer büyük: LLM'lerin hangi içerikleri vitrinin olarak anlamasını gerektiğini aktif olarak yönlendiriyorsun.
Bu Senin İçerik Stratejin İçin Ne Anlama Geliyor
Buraya kadar okuduysan biliyorsun: Yapay zeka için içerik tasarımı seçenek değil, zorunluluk. Ama nereden başlamalı? İşte Storyable'da her audit'te önerdiğimiz operatif sıralama.
Faz 1: Temel Hijyen (1.–2. Hafta)
- En önemli 10 sayfanın HTML hiyerarşisini kontrol et (tam olarak 1× H1, net H2/H3 yapısı)
- Listeleri ve tabloları akıcı metinden çıkar ve semantik olarak doğru işaretle
<article>,<section>,<figure>'ı doğru kullan- robots.txt: GPTBot, ClaudeBot, PerplexityBot, Google-Extended'a açıkça izin ver
Faz 2: Schema Stack (3.–4. Hafta)
- Site genelinde: Organization + SearchAction'lı WebSite uygula
- Alt sayfa başına: BreadcrumbList ekle
- Blog: Article + Person + FAQPage'i her gönderiye tutarlı şekilde
- Google Rich Results Test + Schema.org Validator ile doğrula
Faz 3: Varlık Bağlantısı (5.–6. Hafta)
- Wikipedia, Wikidata, LinkedIn ile
sameAsbağlantıları kur - Knowledge Graph kaydını kontrol et ve gerekirse Google Search Console üzerinden bildir
- Akıcı metinde otoriter kaynaklara cross-entity linkleri ekle
Faz 4: llms.txt ve İzleme (7.–8. Hafta)
- Küratörlü içerik genel bakışıyla domain kök dizinine llms.txt yerleştir
- Sunucu loglarını LLM crawler erişimleri (GPTBot, ClaudeBot, PerplexityBot) için izle
- Citation tracking: Hangi içerikler ChatGPT, Perplexity, Google AI'da alıntılanıyor?
Hannover'dan pratik örnek: Bir Storyable müşterisi – yerel bir online mağaza – schema optimizasyonumuzdan önce Google'da 0 Rich Results ve ChatGPT'de 0 citation'a sahipti. 8 hafta yukarıdaki fazların uygulanmasından sonra: 47 Rich Result, yüzde 18 daha fazla organik trafik, sektörel aramalarda ilk ChatGPT bahisleri. Yatırım: tek seferlik 1.800 Euro. ROI 6 hafta sonra ulaşıldı.
Backlinkler vs. Schema Markup: Dürüst Karşılaştırma
Backlinkleri silmek istemiyoruz – kaliteli backlinkler güven sinyali olarak kalır. Ama ağırlık değişti. İşte 2026 için dürüst karşılaştırma matrisi:
| Faktör | Backlinkler | Schema Markup |
|---|---|---|
| Görünürlük puanı başına çaba | Yüksek (outreach, ilişki yönetimi) | Düşük (tek seferlik uygulama) |
| Ölçeklenebilirlik | Doğrusal, zahmetli | Üstel, çoğaltılabilir |
| Google SERP'lerinde etki | Orta (güven sinyali) | Yüksek (Rich Results, daha yüksek CTR) |
| ChatGPT/Perplexity'de etki | Düşük (LLM'ler link profillerini büyük ölçüde göz ardı eder) | Çok yüksek (Schema = LLM dili) |
| Google AI Overviews'da etki | Orta | Çok yüksek |
| Risk (cezalar) | Yüksek (spam tehlikesi, link satın alma yaptırımları) | Çok düşük (temiz schema = güvenli) |
| Yarı ömür | 1–3 yıl | 5+ yıl |
| Etki başına maliyet | Kaliteli link başına 200–2000 € | Uygulanan schema bloğu başına 50–200 € |
Cevap „Backlinkleri unut" değil, öncelikleri değiştir. 2026'da hâlâ SEO bütçesinin yüzde 80'ini link kurmaya ve sadece yüzde 20'sini teknik yapılandırmaya yatıran, artık var olmayan bir dünya için optimize ediyor.
Sonuç: Yapay Zeka İçin İçerik Tasarımı Yeni Zorunluluk
Yapay zeka için içerik tasarımı Schema Markup ile başlamaz – makinelerin bugün en önemli hedef kitlen olduğunu anlıyor olup olmadığın sorusuyla başlar. İnsanlar evet, hâlâ blog yazıları okuyor. Ama sana makineler üzerinden geliyorlar – Google üzerinden, ChatGPT üzerinden, Perplexity üzerinden, AI Overviews üzerinden. Makine için görünmez olan, insan için ulaşılmaz.
Temiz HTML hiyerarşisi, semantik tablolar ve listeler, JSON-LD ile geçerli Schema Markup, sameAs üzerinden varlık bağlantısı, vitrin olarak llms.txt: Bunlar 2026'da görünürlüğün üzerinde durduğu beş sütun. Backlinkler bir faktör olarak kalıyor – ama artık tek faktör değil.
Şimdi geçiş yapan, hâlâ 2018 SEO mantığında düşünen rakipler karşısında 12-18 aylık bir avantaj kazanır. Storyable olarak Hannover'da görüyoruz: Bu değişimi erken yapan müşteriler, nişlerine hem Google'da hem de yapay zeka cevaplarında aynı anda hakim oluyor. Diğerleri yavaşça kayboluyor.
Web siten makineler tarafından anlaşılıyor mu – yoksa görmezden mi geliniyor?
Web siteni semantik HTML yapısı, Schema Markup eksiksizliği, varlık bağlantısı ve LLM crawler erişimi açısından denetliyoruz. Somut bir aksiyon planı ve entegre etmeye hazır JSON-LD stack alıyorsun – Google Rich Results Test ve Schema.org Validator tarafından doğrulanmış.
Sıkça Sorulan Sorular
Bu konuyla ilgili en önemli soruların hızlı cevapları
Schema Markup 2026'da neden backlinklerden daha önemli?+
Semantik HTML ile Schema Markup arasındaki fark nedir?+
Her web sitesinin 2026'da hangi schema tiplerine sahip olması gerekir?+
ChatGPT gerçekten JSON-LD okur mu?+
Bir SEO eklentisi olan WordPress temiz Schema Markup için yeterli mi?+
Storyable Hannover'da Schema Markup optimizasyonu ne kadara mal olur?+
İlgili Yazılar
Bu konu alanından diğer yazılar
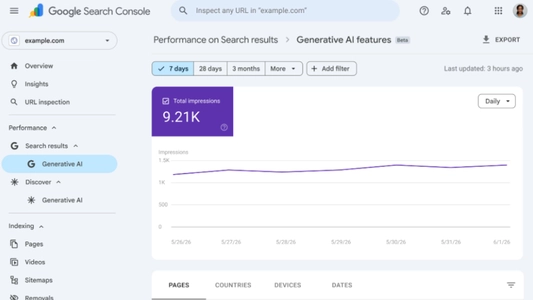
Google Search Console Artık Yapay Zeka Görünürlüğünü Ölçüyor
Google, 3 Haziran 2026'da Search Console'a yeni yapay zeka performans raporlarını ekledi. AI Overviews ve AI Mode'daki gösterim sayılarını artık doğrudan takip edebiliyorsunuz.
İç Bağlantı Mimarisi: Site Yapısıyla Sıralama 2026
İç bağlantı – değeri yetersiz tahmin edilen SEO kaldıracı: Pillar-Cluster, 3-tıklama kuralı ve anchor text 2026'da sıralama potansiyelini nasıl açar.
JavaScript SEO ve Dinamik Renderlama: Google SPA'nı Belki Hiç Okumuyor
JavaScript SEO, Google'ın içeriğini görüp görmediğine karar verir. Googlebot JS'yi nasıl renderlar, SPA'lar neden sıralamada ölür ve Nuxt ile SSR sorunu yapısal olarak nasıl çözer.